



Across biopharma, almost everyone is using AI now: 92% of leaders report using it in at least one non-scientific use case. The pattern that tends to follow is familiar enough to be a genre. A pilot produces a promising result, leadership gets excited, and then the project quietly stalls, never quite making it into the daily work it was supposed to change.
When that happens, the instinct is to question the model, but most of the time that's the wrong place to look. The models usually do what they were built to do; what they can't do is run on a foundation that was never built for them.
That gap — between a pilot that works and an operation that actually runs on AI — was the subject of From Orchestration to AI-Enabled Intelligence: The Next Era of R&D Operations, the first session in our AI in Procurement & Ops Webinar Series, held June 17. Chris Zan (SVP Strategy & Operations) and Monica Tan (SVP Product & Design), with moderator Ankita Iyer Goswami (Head of Product Marketing), made a case that's easy to state and hard to act on: the limiting factor in R&D operations isn't the AI, it's the infrastructure underneath it.
Most AI pilots in biopharma don't fail because of the model — they stall because the data infrastructure underneath was never built for production.Why Do AI Pilots Stall Before They Scale?
Chris opened on the paradox: adoption is nearly universal, yet moving a pilot into production is still rare. If the technology is advancing this fast, why aren't organizations advancing with it?
His answer had little to do with models and everything to do with the ground they stand on. The most common reason pilots fail is data that's incomplete, inconsistent, or trapped in formats AI can't use. Two more reasons compound it: security and compliance concerns that keep teams boxed into small experiments, and systems so fragmented that embedding AI into real work becomes a project of its own. When we asked attendees which of these they'd run into, fragmented systems and workflows was the most common answer.
A pilot and a production system are not the same environment. One runs in a controlled slice, with clean data, a contained workflow, and a single team; the other contends with messy data, a dozen systems, and real handoffs between real people. The pilot doesn't fail because the AI got worse, it fails because the conditions changed and the foundation underneath couldn't hold it. You can't build intelligence on top of fragmentation.
That's why most teams are stuck in the middle. When we polled where organizations sit on their AI journey, the largest group said they're still exploring, a smaller group is scaling select use cases, and only a few have AI embedded in daily work. If your organization is somewhere in that middle, the bottleneck usually isn't ambition, it's the foundation.
Why Outsourced R&D Feels It First
For teams that run R&D through external partners, fragmentation isn't an occasional problem, it's the default condition. The information needed to reason about a single program is scattered across suppliers, procurement, scientists, finance, contracts, invoices, and project records, each in its own format and its own system. Point AI at that and it doesn't clear the mess, it surfaces it.
The cost of that isn't abstract. Every hour a scientist spends reconciling records or chasing the status of an order is an hour not spent on the science, and the same friction that traps AI in pilot mode is what slows the research itself. That is the real reason this gap matters: it isn't an IT inconvenience, it's drag on discovery.
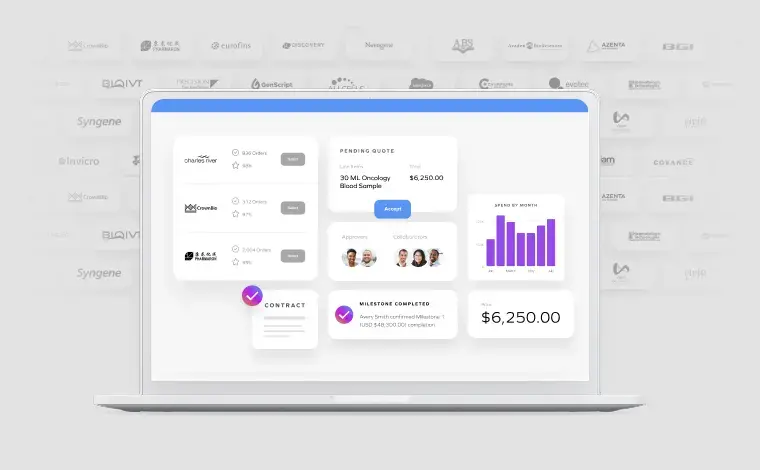
AI pilots don't stall because of the AI. They stall because the infrastructure underneath isn't ready. Science Exchange technology is what makes the difference here: one system of normalized, structured data. Here's what "ready" actually looks like for R&D operations teams and how we're using that infrastructure to innovate.
Fragmented supplier data doesn't just slow procurement — it traps AI in pilot mode and steals hours from the scientists who should be doing science.How We Are Innovating
What does a foundation AI can run on actually look like? Monica's answer started with data, and specifically with the shape of it rather than the volume. Science Exchange holds 15 years of first-party operational data, generated inside live workflows and normalized into one consistent structure across thousands of projects. AI struggles when every project looks different, and works when it can recognize patterns across comparable work at scale. That structure is the prerequisite everything else depends on.
With it in place, intelligence stops feeling like a bolt-on. In the session, the Science Exchange Assistant answered plain-language questions about requests, approvals, and spend, pointing to where spend was concentrated, the kind of question that normally means commissioning a report.
Two further capabilities, Savings Finder and Purchasing Assistant, were shown as in-development previews of where this is heading. Savings Finder proactively surfaces opportunities for improved rate cards and competitive sourcing, enabling data-driven decisions from historical purchasing patterns that are difficult to uncover manually. The Purchasing Assistant allows users to find the right suppliers for their work through conversational, natural language and weigh confidence signals that matter. The full walkthroughs are in the recording, but the point on the page is simpler: none of it is possible without the structured foundation underneath.
A Vision for the Future
The shift Monica left the audience with was one of posture. Most operational data today tells you what already happened. The direction of travel is toward systems that let teams see what's coming, so decisions about cost, suppliers, and risk get made earlier and with more confidence, and routine work that never needed a person stops consuming one. When we asked which forward-looking capability would create the most value, attendees pointed first to predictive recommendations, the ability to anticipate needs and surface risk before it becomes a delay.
Concluding Remarks
The through line, from Chris's market framing to Monica's product direction, holds together as one idea: the AI opportunity in R&D operations is real, and the thing standing in its way isn't the AI.
Teams crossing from pilot to production aren't layering a smarter model on top of the same tangle. They're building the foundation that makes a smart model useful: connected supplier data, structured spend, and workflows that run reliably and stay compliant. Once that's in place, intelligence follows, and the payoff isn't a tidier operation for its own sake, it's giving researchers back the time and the certainty to do the work that actually matters.
Missed the session? Watch the on-demand recording.
Or to see how Science Exchange's AI capabilities work against your specific supplier and spend data, request a demo.
This is the first post in the AI in Procurement & Ops Webinar Series. If you missed our April session on the Science Exchange connected ecosystem, that recap is here.
